
阶段工作总结
人脸风格化可行性方案
目前路线为 多数据源启动数据,小样本训练 Lora 后,使用数据合成循环管道,不断过滤优化数据,生成大量数据,最终训练出高质量的指令引导的人脸风格化模型
一、现有开源工具生成
1、通过 EasyControl 生成 Ghibli 风格的人脸数据
https://github.com/Xiaojiu-z/EasyControl
2、通过 豆包 生成部分风格数据
还需注意是否开源、开源协议
例如 3D动漫、插画、绘本 … 均有不错的表现
3、通过 HiDream-I1 生成数据
https://github.com/HiDream-ai/HiDream-I1
在线测试,风格化后均为半身照,这意味着只能专门处理半身人像
部署显存需 70GB 以上,待实验
Step-1X
https://huggingface.co/stepfun-ai/Step1X-Edit
以 Ghibli 风格图像为 Bridge 可以得到较好的风格化效果,不过受 Ghibli 影响较大
4、SD 3.5
https://platform.stability.ai/
在以往实验中,SD 3.5 生成其预设的风格能力还是非常不错的,例如pixel、cyberpunk,不过模型还没有开源
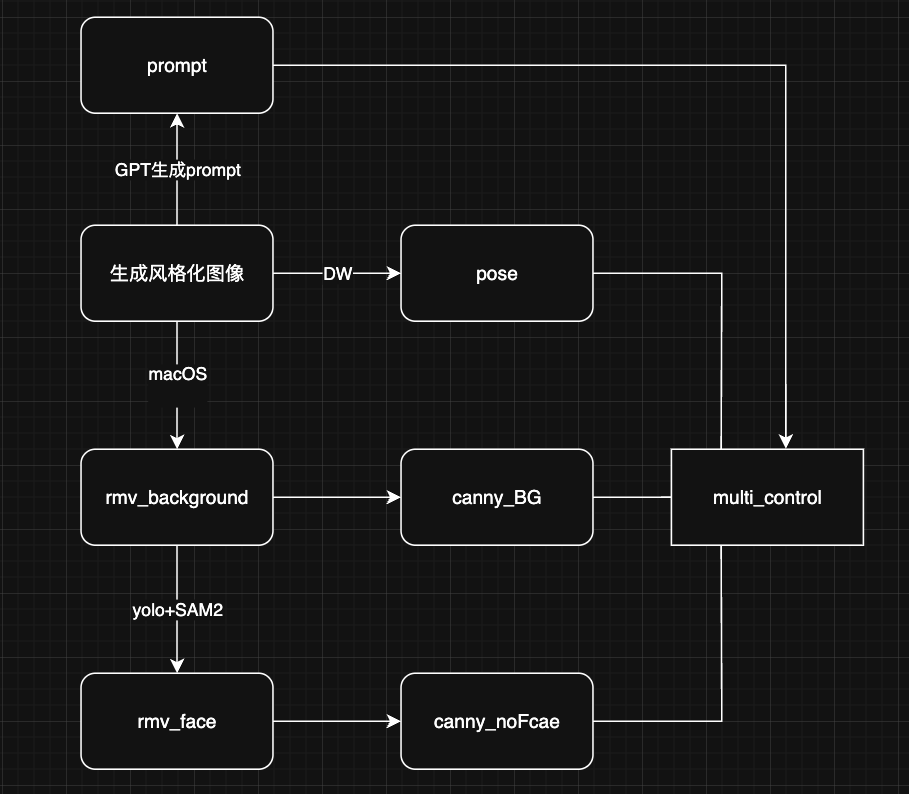
二、Multi_Control 面部解偶 deStyle
数据生成步骤中的
核心创新点
使用 FLUX+ControlNet 为base,通过分别提取人脸和背景 canny,同时设有不同的权重,通过 prompt 引导实现已风格化图像的去风格化任务。
基于现有实验拟定的最佳组合参数如下
1 | control_image=[ |
尝试过的部分失败组合
Pose + Canny_backgroud , 缺少面部信息,模型生成面部内容质量很低
Canny_face + Canny_backgrond , 缺少
Pose的引导与平衡,Canny完全占主导地位,效果不佳…+ Depth , 高权重下
Depth的阴影部分严重影响生成图片的背景,使背景变暗,低权重几乎没有作用
当前组合下的几个疑难点
由于目前仅基于 FFHQ 数据集测试,均为人脸或小半身人脸,且于
Canny控制下Pose作用甚微,主要起补充信息作用,后续若扩张为半身人像或全身人像,该参数可能需重新考虑Double Canny 权重拮抗,若人脸
canny权重高于背景,则可能会出现过拟合的状态,eg:Ghibli 的大眼睛,若背景canny权重高于人脸,则可能会出现丢失面部内容信息,所以这两个参数还需不断测试,或探索别的办法来解决这一问题prompt 质量严重影响生成质量,这是最让我头疼的一点,同样参数下,不同的
prompt产出的内容质量差别不小,个人认为prompt中应至少含有以下几点信息头发颜色,衣服颜色,背景颜色,肤色,真实感,真实皮肤纹理等等step、guidance_scale 的值同样值得推敲
后续应批量处理数据,不断改进参数,找到适配这样去风格处理手段的风格,测试 Multi_control 和 Single_control的差异
不同风格适宜参数
| 风格 | pose | cy_BG | cy_noFace | step | guidance_scale |
|---|---|---|---|---|---|
| 3D风格 | 0.33 | 0.35 | 0.2 | 40 | 10 |
| end | 0.3 | 0.4 | 0.3 | - | - |
| Ghibli | 0.33 | 0.5 | 0.3 | 45 | 8 |
| end | 0.3 | 0.8 | 0.65 | - | - |
| WaterColor | 0.33 | 0.5 | 0.3 | 45 | 8 |
| end | 0.3 | 0.8 | 0.65 | - | - |
| monet | 0.33 | 0.3 | 0.25 | 40 | 10 |
| end | 0.3 | 0.7 | 0.55 | - | - |
| sketch | 0.33 | 0.5 | 0.5 | 40 | 10 |
| end | 0.3 | 0.7 | 0.55 | - | - |
| Disney | 0.33 | 0.4 | 0.25 | 40 | 10 |
| end | 0.3 | 0.7 | 0.35 | - | - |
pixel
可以使用 Ghibli 当 Bridge 通过 Step-1X StyleTransfer 得到 ,sd 3.5 可以很好的处理 pixel 风格
3D
遗留问题:太不稳定了 但是只需要 100 200 张的话可以用量堆出来
moent
遗留问题:肤色、男生
FLUX 能力有限
在我测试的 极简 美漫 星月夜 梵高 … 效果不佳